Research Wiki
Research was being generated. None of it was being used.
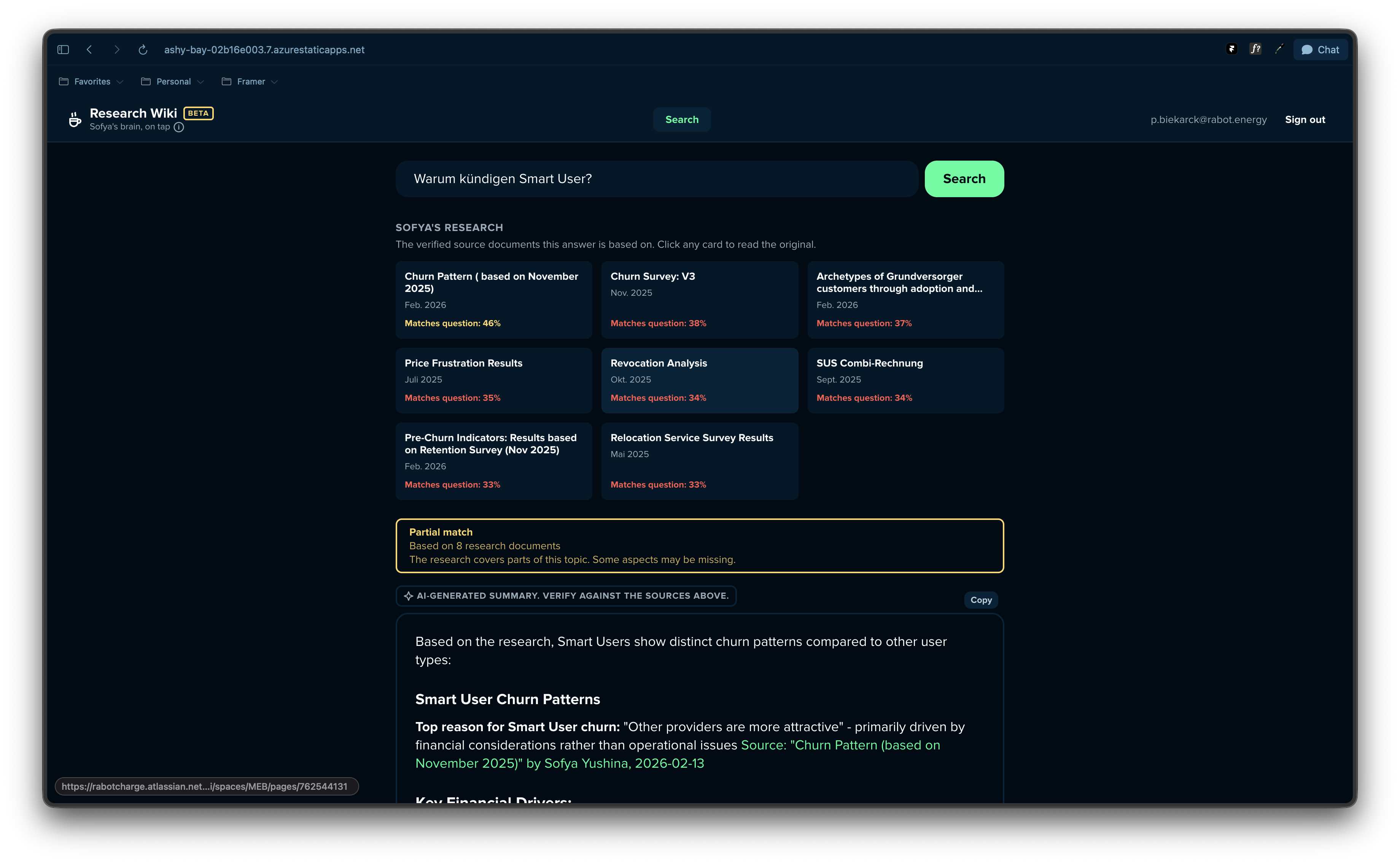
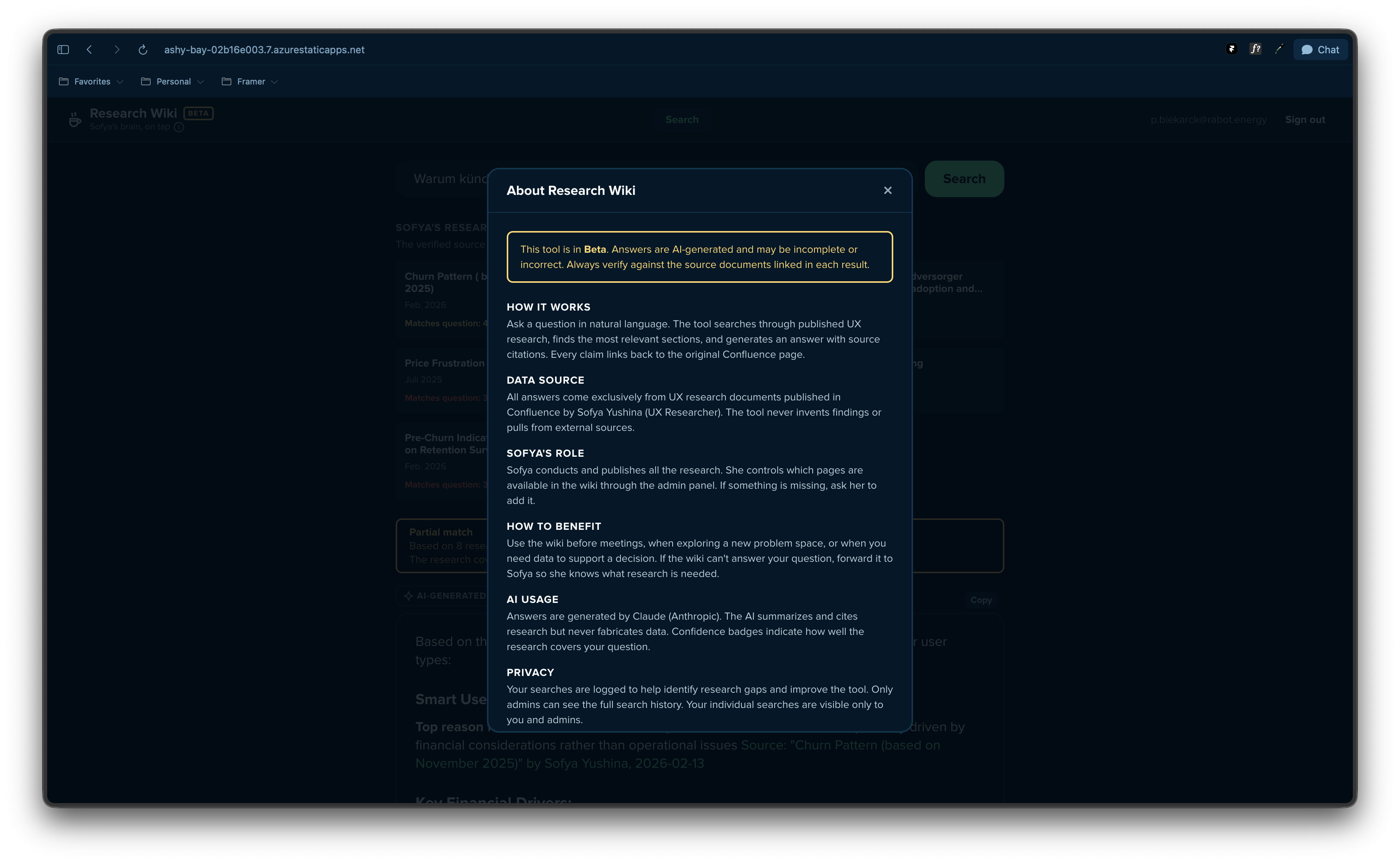
UX insights lived in Confluence and died there. The Research Wiki makes existing research accessible to anyone on the team, in natural language, with sources cited and confidence scored.
3 days
from idea to working pilot · AI-augmented design and build
RABOT Energy · 2025 · ~1.5 weeks part-time
Design Leadership
Design Ops
AI-Augmented Build
Product Strategy